
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |
- matrix trnasformations
- Big-Oh 예제
- trivial solution
- 이진 탐색
- NumPy
- 배열 섞기
- Big-Oh notation
- itertools
- 일차변환
- nonhomogeneous linear system
- linear dependence
- 빅오 표기법
- Big-O 예제
- recursive algorithms
- matrix fo a linear transformation
- python
- includepdf
- Big Omega
- homogeneous linear system
- nontrivial solution
- Big Theta
- 페이지 겹칩
- 코틀린 시작하기
- 랜덤 순서 배열
- 재귀함수
- 빅오메가
- one-to-one
- 알고리즘 분석의 실례
- 코틀린 Hello World!
- 빅세타
- Today
- Total
목록분류 전체보기 (161)
코딩 연습
 1. 코틀린 시작하기 - "Hello, World!"
1. 코틀린 시작하기 - "Hello, World!"
1. TRY KOTLIN 페이지 이용하기사실 코틀린을 가장 빠르게 시도할 수 있는 방법은 TRY KOTLIN 페이지에 접속하는 것이다. 이 페이지에 접속하면 다음과 같은 화면을 볼 수 있고, 오른쪽 창에 아래 그림과 같은 코틀린 코드를 입력한 후, 오른쪽 위쪽의 Run 버튼을 눌러주면 아래 쪽에서 그 결과를 확인할 수 있다. 2. IntelliJ IDEA 사용하기두 번째 방법은 JetBrains 의 IntelliJ IDEA 를 이용하는 방법이다. IDEA 다운로드 페이지에서 자신의 OS 를 선택한 후에 Community 버전을 다운로드 받고 설치하도록 하자. (community 버전은 무료다.) 설치 후에 실행하면 아래와 같은 창이 나온다. 여기서 Create New Project 를 선택한다. 그럼 다..
 이진 탐색 알고리즘 (binary search algorithm)
이진 탐색 알고리즘 (binary search algorithm)
주어진 배열에서 특정한 요소 target 을 찾아내는 상황을 가정해 봅시다. 가장 쉽게 떠 올릴 수 있는 방법은 배열의 요소 하나하나와 target 값이 같은지를 순차적으로 모두 비교하는 것입니다. 만약 배열의 크기가 $n$ 이라고 한다면 이 알고리즘의 시간복잡도를 Big-Oh notation을 이용하요 나타낸다면 $O(n)$ 이 되겠죠. 그렇지만 이것보다 훨씬 빠르게 target 을 찾아내는 방법도 있습니다. 우리가 살펴봐야 할 요소들의 개수를 절반으로 줄여가면서 탐색을 하는 것이죠. 이런식으로 탐색하는 방법이 바로 이진 탐색 알고리즘입니다. 다만 이진 탐색(binary search)은 오름 차순으로 정렬된 배열에만 적용할 수 있다는 단점이 있습니다. (앞으로 내용을 보시면 아시겠지만 오름차순으로 정렬..
이전에 알아봤던 Big-Oh Notation 의 실례들을 살펴보자. $O(1)$파이썬의 list 클래스에서는 각 리스트의 길이를 저장하고 있는 변수가 존재하여 리스트 요소 하나하나를 반복적으로 접근하여 세지 않고도 그 길이를 즉각 반환하여 준다. 이런 측면에서 본다면 리스트의 길이를 구하는 것은 $O(1)$ 에 해당된다고 할 수 있다. 또한 파이썬의 리스트는 array-based sequences 로 실행되기 때문에 각각의 요소들은 연속적인 저장 공간에 하나씩 저장이 되고, 이들은 모두 인덱스를 이용하여 직접 접근할 수 있다. 예를 들어, input_data[i] 라고 하면 input_data 라는 리스트의 인덱스 i 인 저장소의 값을 그대로 반환해 준다. 따라서 이것 역시 $O(1)$ 에 해당된다고 할..
 Big-Oh Notation (빅-오 표기법)
Big-Oh Notation (빅-오 표기법)
프로그램의 실행시간을 흔히 시간복잡도(time complexity)라고 말한다. 알고리즘의 분석에 있어서 이 시간복잡도를 입력 자료의 크기 $n$ 의 함수로 나타내는 것이 일반적이다. 예를 들어, 다음과 같은 파이썬 코드가 있다고 하자. def find_max(input_data): maximum = input_data[0] for element in input_data: if element > maximum: maximum = element return maximum 위의 파이썬 코드는 리스트 형태로 주어지는 input_data 의 요소 중 그 값이 가장 큰 것을 반환하는 함수 find_max 를 나타낸다. 이때 이 코드의 실행시간은 중간에 있는 for-loop 에 가장 큰 영향을 받게 되리라는 것을 ..
 (재귀함수) $n!$ ($n$ 의 계승) 구하기
(재귀함수) $n!$ ($n$ 의 계승) 구하기
재귀함수(recursive function) 이란 함수내에서 자기 자신을 호출하는 함수이다. 재귀함수가 어떤 식으로 동작하는지는 재귀함수를 이용하여 $n!$ 을 구해보면 쉽게 알 수 있다.$n!$ 은 혹은 $n$ 의 계승은 다음과 같이 $1$ 부터 $n$ 까지의 곱으로 정의된다.$$ n! = \prod \limits_{k=1}^n k= n \times (n-1) \times \cdots \times 2 \times 1$$물론 루프(loop)를 이용하여 $n!$ 을 구할 수 있지만, 재귀함수를 이용할 수도 있다. 재귀함수를 이용한 $n!$ 구하기 파이썬 코드는 다음과 같다. def factorial(n): if n == 0: return 1 else: return n * factorial(n - 1) nu..
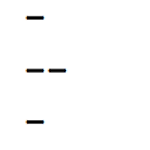 (재귀함수) 자(ruler)의 눈금 그리기
(재귀함수) 자(ruler)의 눈금 그리기
"자(ruler)의 눈금 그리기"는 자에서 사용할 가장 긴 눈금의 길이과 자의 크기를 입력하면 자의 눈금이 그려지도록 프로그래밍 하는 문제이다. 예를 들어, (1) 가장 긴 눈금의 길이를 3, 자의 크기를 3으로 입력하면 다음과 같은 눈금이 그려져야 한다. 그림에서 볼 수 있듯이 주 눈금은 길이 3인 '---' 로 표시했고, 1단위를 4등분하여 2등점은 길이 2인 '--' 로, 4등분점은 길이 1인 '-' 로 표시하였다. 또한 주 눈금을 표시하고 나면 옆에 눈금에 해당하는 숫자를 표기해 주었다. (2) 가장 긴 눈금의 길이를 4, 자의 크기를 2로 입력하면 다음과 같은 눈금이 그려져야 한다.주 눈금은 길이 4인 '----'로 표시했고, 1 단위를 8등분하여 2등분점은 길이 3인 '---' 로, 4등분점은..
numpy 모듈의 nonzero 함수는 요소들 중 0이 아닌 값들의 index 들을 반환해 주는 함수이다. 다음의 예제를 보자. >>> import numpy as np >>> a=np.array([1, 0, 2, 3, 0]) >>> np.nonzero(a) (array([0, 2, 3]),) 0이 아닌 값 1, 2, 3 의 index 인 0, 2, 3 을 array 형태로 리턴해 주는 것을 볼 수 있다. 그런데 a 가 2D array 가 되면 그 결과를 보기가 좀 복잡해 진다. >>> a=np.array([[1, 0, 7], [8, 1, 0], [1, 0, 0]]) >>> a array([[1, 0, 7], [8, 1, 0], [1, 0, 0]]) >>> np.nonzero(a) (array([0, 0..
numpy 모듈의 amax 함수는 array 의 최댓값을 반환하는 함수이다. 다음 예를 보자. >>> import numpy as np >>> a = np.range(4) >>> a array([0, 1, 2, 3]) >>> np.amax(a) 3 위 예에서 볼 수 있듯이 np.amax(a) 는 array [0, 1, 2, 3] 의 요소 중 가장 큰 값이 3을 반환하는 거을 알 수 있다.amax 함수는 행렬 (matrix) 에서 행이나 열 각각에 대한 최댓값을 반환해 주기도 한다. >>> a = np.arange(4).reshape((2, 2)) >>> a array([[0, 1], [2, 3]]) >>> np.amax(a, axis=0) array([2, 3]) >>> np.amax(a, axis=1)..
numpy.arange([start, ] stop, [step, ] dtype=None) numpy 모듈의 arange 함수는 반열린구간 [start, stop) 에서 step 의 크기만큼 일정하게 떨어져 있는 숫자들을 array 형태로 반환해 주는 함수다. stop 매개변수의 값은 반드시 전달되어야 하지만 start 는 step 은 꼭 전달되지 않아도 된다. start 값이 전달되지 않았다면 0 을 기본값으로 가지며, step 값이 전달되지 않았다면 1 값을 기본값으로 갖게 된다. dtype 의 경우 결과로 반환되는 array 이의 type 을 지정할 때 사용한다. dtype 값이 주어지지 않는 경우 전달된 다른 매개 변수로부터 type 을 추론하게 된다. 다음의 예를 보면 쉽게 이해할 수 있을 것이다..
파이썬의 내장함수 all 은 다음과 같다. def all(iterable): for element in iterable: if not element: return False return True 함수 all 은 매개변수로 iterable (리스트, 튜플, 딕셔너리 등등) 를 갖는다. 함수 all 은 iterable 내의 모든 요소가 참이거나 혹은 iterable 이 비어 있다면 True 를 반환하고, 그 외의 경우에는 False 를 반환하는 함수이다. 즉, iterable 내의 요소 중 단 하나라도 거짓인 경우에는 False 를 반환한다. 파이썬에서는 0을 False 로 1은 True 로 인식한다. 다음의 예제를 보면 쉽게 이해할 수 있다. >>> all([]) True >>> all([1, 2, 3, ..